단항 논리 회귀(Logistic Regression)
- 분류를 할 때 사용하며, 선형 회귀 공식으로부터 나왔기 때문에 논리회귀라는 이름이 붙여졌다.
시그모이드(Sigmoid) 함수
- 예측값을 0에서 1 사이의 값으로 되도록 만든다.
- 0에서 1사이의 연속된 값을 출력으로 하기 때문에 보통 0.5(임계값)를 기준으로 구분한다.

# 모듈 import
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt# 난수 생성과정을 일관되게 만들이 위함이다.
# 코드를 실행할 때 마다 동일한 난수 순서를 얻을 수 있게 되며
# 이는 모델 학습 및 실험의 일관성을 보장한다고 한다.
torch.manual_seed(2024)# 예제
x_train = torch.FloatTensor([[0], [1], [3], [5], [8], [11], [15], [20]])
y_train = torch.FloatTensor([[0], [0], [0], [0], [0], [1], [1], [1]])
print(x_train.shape)
print(y_train.shape)
# 그래프에 나타내기
plt.figure(figsize=(8, 5))
plt.scatter(x_train, y_train)
# Sequential을 사용하면 모델이 내부에 함수들을 적용하게 된다.
model = nn.Sequential(
nn.Linear(1, 1),
nn.Sigmoid()
)
print(model)
# W: 0.9437, b: -0.7614 가 나오는 것을 볼 수 있다.
print(list(model.parameters()))
비용함수
- 논리회귀에서는 nn.BCELoss() 함수를 사용하여 Loss를 계산한다.
- Binary Cross Entropy
# 위에서 만든 모델 사용
y_pred = model(x_train)
y_pred
# 비용함수로 오차값 구하기
loss = nn.BCELoss()(y_pred, y_train)
loss
# 최적화 값을 구하기 위한 함수
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 반복 횟수
epochs = 1000
# 반복문 사용하여 학습
for epoch in range(epochs + 1):
y_pred = model(x_train)
loss = nn.BCELoss()(y_pred, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 ==0:
print(f"Epoch: {epoch}/{epochs} Loss: {loss:.6f}")
# W: 0.2662, b: -2.1494
print(list(model.parameters()))
# 다른값 넣어서 테스트 해보기
x_test = torch.FloatTensor([[9]])
y_pred = model(x_test)
print(y_pred)
# 임계치 설정하기
# 0.5보다 크거나 같으면 1
# 05. 보다 작으면 0
y_bool = (y_pred >= 0.5).float()
print(y_bool)
다항 논리 회귀
# 예제
x_train = [[1, 2, 1, 1],
[2, 1, 3, 2],
[3, 1, 3, 4],
[4, 1, 5, 5],
[1, 7, 5, 5],
[1, 2, 5, 6],
[1, 6, 6, 6],
[1, 7, 7, 7]]
y_train = [0, 0, 0, 1, 1, 1, 2, 2]# Tensor 형식으로 변경
x_train = torch.FloatTensor(x_train)
y_train = torch.LongTensor(y_train)
print(x_train.shape)
print(y_train.shape)
# 모델 생성
model = nn.Sequential(
nn.Linear(4, 3)
)
print(model)
# 예측
y_pred = model(x_train)
print(y_pred)
CrossEntropyLoss
- 교차 엔트로피 손실은 PyTorch에서 제공하는 손실 함수 중 하나로 다중 클래스 분류 문제에서 사용한다.
- 소프트맥스 함수와 교차 엔트로피 손실 함수를 결합한 형태이다.
- 소프트 맥스 함수를 적용하여 각 클래스에 대한 확률 분포를 얻는다.
- 각 클래스에 대한 로그 확률을 계산한다.
- 실제 라벨과 예측 확률의 로그 값 간의 차이를 계산한다.
- 계산된 차이의 평균을 계산하여 최종 손실값을 얻는다.
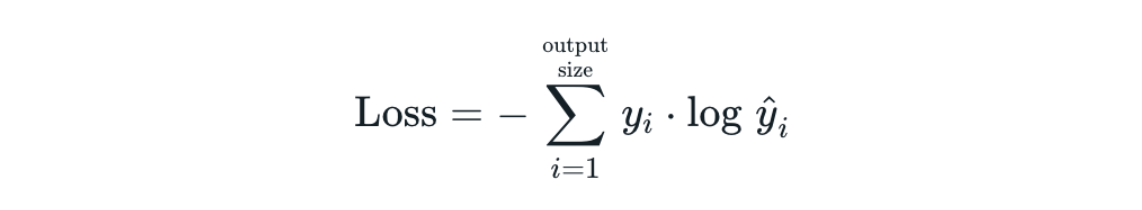
SoftMax
- 다중 클래스 분류 문제에서 사용되는 함수로 주어진 입력 벡터의 값을 확률 분포로 변환한다.
- 각 클래스에 속할 확률을 계산할 수 있으며 각 요소를 0과 1 사이의 값으로 변환하여 이 값들의 합은 항상 1이 되도록 한다.
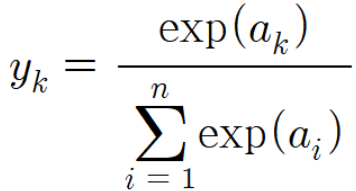
- 각 입력 값에 대해 지수 함수를 적용한다.
- 지수 함수를 적용한 모든 값의 합을 계산 후, 각 지수 합으로 나누어 정규화를 한다.
- 정규화를 통해 각 값은 0과 1 사이의 확률 값으로 출력한다.
# 손실값 계산
loss = nn.CrossEntropyLoss()(y_pred, y_train)
print(loss)
# 최적화 값을 구하기 위한 함수
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 반복 횟수
epochs = 1000
# 훈련
for epoch in range(epochs + 1):
y_pred = model(x_train)
loss = nn.CrossEntropyLoss()(y_pred, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
print(f"Epoch: {epoch}/{epochs} Loss: {loss:.6f}")
# 다른 값으로 테스트 해보기
x_test = torch.FloatTensor([[1, 7, 8, 7]])
y_pred = model(x_test)
print(y_pred)
# 예측값과 확률 구하기
y_prob = nn.Softmax(1)(y_pred)
y_prob
# [[2.3060e-07, 2.0376e-02, 9.7962e-01]] # 확률값으로 나옴
print(f"0일 확률: {y_prob[0][0]:.2f}")
print(f"1일 확률: {y_prob[0][1]:.2f}")
print(f"2일 확률: {y_prob[0][2]:.2f}")
테스트 값으로 [1, 7, 8, 7] 을 넣었을 때, 2일 확률이 98% 가 나왔다. 위를 살펴보면 [1, 7, 7, 7] 값을 기본값으로 넣었을 때 반환값은 2로 지정했다. 따라서 예측을 잘했다고 볼 수 있다.
# 가장 높은 확률을 뽑기
torch.argmax(y_prob, axis=1)
경사하강법의 종류
- 배치 경사 하강법
- 가장 기본적인 경사 하강법(Vanilla Gradient Descent)
- 데이터셋 전체를 고려하여 손실함수를 계산한다.
- 한 번의 Epoch에 모든 파라미터 업데이트를 다 한 번만 수행한다.
- batch의 개수와 Iteration은 1이고, Batch Size는 전체 데이터의 개수이다.
- 파라미터 업데이트할 때 한 번의 전체 데이터셋을 고려하기 때문에 모델 학습 시 많은 시간과 메모리가 필요하다는 단점이 있다.
- 확률적 경사 하강법
- 확률적 경사 하강법(Stochastic Gradient Descent)은 경사 하강법이 모델 학습 시 많은 시간과 메모리가 필요하다는 단점을 보완하기 위해 제안된 기법이다.
- Batch Size를 1로 설정하여 파라미터를 업데이트하기 때문에 배치 경사 하강법보다 훨씬 빠르고 적은 메모리로 학습을 진행한다.
- 파라미터 값의 업데이트 폭이 불안정하기 때문에 정확도가 낮은 경우가 생길 수 있다.
- 미니 배치 경사 하강법
- 미니 배치 경사 하강법(Mini-Batch Gradient Descent)은 Batch Size를 설정한 size로 사용한다.
- 배치 경사 하강법보다 모델 속도가 빠르고, 확률적 경사 하강법보다 안정적인 장점이 있다.
- 딥러닝 분야에서 가장 많이 활용되는 경사 하강법이다.
- 일반적으로 Batch Size를 16, 32, 64, 128과 같이 2의 n제곱에 해당하는 값으로 사용하는 게 관례적이다.
경사 하강법의 여러 가지 알고리즘
- SGD(확률적 경사 하방법)
- 매개변수 값을 조정 시 전체 데이터가 아니라 랜덤으로 선택한 하나의 데이터에 대해서만 계산하는 방법이다.
- 모멘텀(Momentum)
- 관성이라는 물리학의 법칙을 응용한 방법이다.
- 경사 하강법에 관성을 더해준다.
- 접선의 기울기에 한 시점 이전의 접선의 기울기 값을 일정한 비율만큼 반영한다.
- 아다그라드(Adagrad)
- 모든 매개변수에 동일한 학습률(learning rate)을 적용하는 것은 비효율적이라는 생각에서 만들어진 학습 방법이다.
- 처음에는 크게 학습하다가 조금씩 작게 학습시키는 방법이다.
- 아담(Adam)
- 모멘텀 + 아다그라드
- AdamW
- Adam optimizer의 변형
- Adam의 일부 약점(가중치 감쇠)과 성능 향상을 위해 고안되었다.
와인 품종 예측해 보기
- sklearn.datasets.load_wine : 이탈리아의 같은 지역에서 재배된 세 가지 다른 품종으로 만든 와인을 화학적으로 분석한 결과에 대한 데이터셋이다.
- 13개의 성분을 분석하여 어떤 와인인지 구별하는 모델을 구축하자.
- 데이터를 섞은 후 train 데이터를 80%, test 데이터를 20%로 하여 사용하자.
- Adam을 사용
- 테스트 데이터의 0번 인덱스가 어떤 와인인지 출력하고, 정확도를 출력
# 필요한 모듈 import
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split# 데이터를 담아준다.
x_data, y_data = load_wine(return_X_y=True, as_frame=True)# Tensor 형태로 변환
x_data = torch.FloatTensor(x_data.values)
y_data = torch.LongTensor(y_data.values)
print(x_data.shape)
print(y_data.shape)
# 훈련/테스트용 데이터 적용하기
X_train, X_test, y_train, y_test = train_test_split(x_data, y_data,
test_size=0.2,
random_state=2024)
print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)
# 모델을 생성 13개가 들어가면 3개로 반응하게 한다.
model = nn.Sequential(
nn.Linear(13, 3)
)
# 최적화를 계산하는 함수
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 반복 횟수
epochs = 1000
# 반복문을 사용하여 학습
for epoch in range(epochs + 1):
y_pred = model(X_train)
loss = nn.CrossEntropyLoss()(y_pred, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 100 == 0:
y_prob = nn.Softmax(1)(y_pred)
y_pred_index = torch.argmax(y_pred, axis=1)
y_train_index = y_train
accuracy = (y_train_index == y_pred_index).float().sum() / len(y_train) * 100
print(f"Epoch: {epoch:4d}/{epochs} Loss: {loss:.6f} Accuracy: {accuracy:.2f}")
# 예측
y_pred = model(X_test)
y_pred[:5]
# 예측값과 확률 구하기
y_prob = nn.Softmax(1)(y_pred)
y_prob[:5]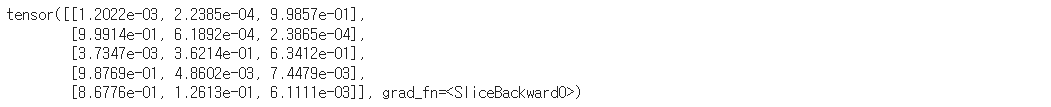
print(f"0번일 품종일 확률: {y_prob[0][0]:.2f}")
print(f"1번일 품종일 확률: {y_prob[0][1]:.2f}")
print(f"2번일 품종일 확률: {y_prob[0][2]:.2f}")
y_pred_index = torch.argmax(y_prob, axis=1)
accuracy = (y_test == y_pred_index).float().sum() / len(y_test) * 100
print(f"테스트 정확도는 {accuracy:.2f}% 입니다!")
'Python > 머신러닝, 딥러닝' 카테고리의 다른 글
| Python 딥러닝 (0) | 2024.06.24 |
|---|---|
| Python 머신러닝, 딥러닝 데이터 로더 (0) | 2024.06.24 |
| Python 머신러닝, 딥러닝 파이토치로 구현한 선형 회귀 (0) | 2024.06.18 |
| Python 머신러닝, 딥러닝 파이토치 (0) | 2024.06.18 |
| Python 머신러닝 다양한 모델 적용하기 (0) | 2024.06.17 |