DataSet
- 특정 작업을 위해 데이터를 관련성 있게 모아 놓은 것이다.
- 데이터셋은 다양한 형태로 존재할 수 있으며, 데이터 항목들은 구조화된 방식(행과 열로 구성)으로 배열된다.
- 데이터셋의 사용
분석: 데이터를 분석하여 패턴을 찾고 결론을 도출한다.
시각화: 데이터를 시각적으로 표현하여 이해하기 쉽게 만든다.
모델링: 머신러닝 모델을 훈련시키기 위해 사용된다.
보고서 작성: 데이터를 기반으로 보고서나 인사이트를 생성한다.
인공지능 분야 데이터셋 제공 사이트
- Scikit-learn
- https://scikit-learn.org/stable/index.html
scikit-learn: machine learning in Python — scikit-learn 1.5.0 documentation
Comparing, validating and choosing parameters and models. Applications: Improved accuracy via parameter tuning. Algorithms: Grid search, cross validation, metrics, and more...
scikit-learn.org
- Kaggle
- 구글에서 운영하는 전 세계 AI개발자, 데이터 사이언티스트들이 데이터를 분석하고 토론할 수 있는 자료 등을 제공한다.
- 데이터 분석 및 머신러닝, 딥러닝 대회를 개최한다.
- 데이터셋, 파이썬 자료, R자료 등을 제공한다.
Kaggle: Your Machine Learning and Data Science Community
Kaggle is the world’s largest data science community with powerful tools and resources to help you achieve your data science goals.
www.kaggle.com
- Dacon
- 국내 최초 AI 해커톤 플랫폼이다.
- 전문 인력 채용과 학습할 수 있는 여러 가지 AI자료 등을 제공한다.
데이터사이언티스트 AI 컴피티션
10만 AI 팀이 협업하는 데이터 사이언스 플랫폼. AI 경진대회와 대상 맞춤 온/오프라인 교육, 문제 기반 학습 서비스를 제공합니다.
dacon.io
- AI허브
- 한국지능정보사회진흥원이 운영하는 AI 통합 플랫폼이다.
- AI 기술 및 제품 서비스 개발에 필요한 AI 인프라를 제공한다.
AI-Hub
[한국어] 한국어 음성 #일상 대화 # 쇼핑 대화 # 정치 대화 # 경제 대화 # 취미 대화 # AI 비서 # 동시통역 # 감성형 대화 음성지능 서비스 조회수 53,187 관심등록 125 다운수 14,155
www.aihub.or.kr
iris DataSet
scikit-learn 홈페이지에서 DataSet을 가져온다.( 상단 카테고리 "API" -> 좌측 카테고리 "sklearn.datasets")

참고로 iris는 붓꽃이라고 한다. 3가지 다른 종류의 붓꽃에 대한 측정값을 포함한다.
# iris DataSet을 가져오는 방법
from sklearn.datasets import load_iris# 데이터셋 확인
iris = load_iris()
iris
# 데이터셋 설명 확인
# print(iris[DESCR])
print(iris.DESCR)
설명을 보면 sepal length, sepal width, petal length, petal width가 있는데 이들을 기준으로 분류한 것 같다.

# 데이터셋에 실제 데이터 가져오기
data = iris.data
data
# 데이터셋에서 특징들의 이름 가져오기(데이터 프레임을 만들 때 열(column)으로 사용할 것들)
feature_names = iris.feature_names
feature_names
iris 데이터셋을 확인했으니 이제 데이터 프레임을 만들기 위해 pandas를 import 해준다.
import pandas as pd
df_iris = pd.DataFrame(data, columns=feature_names)
df_iris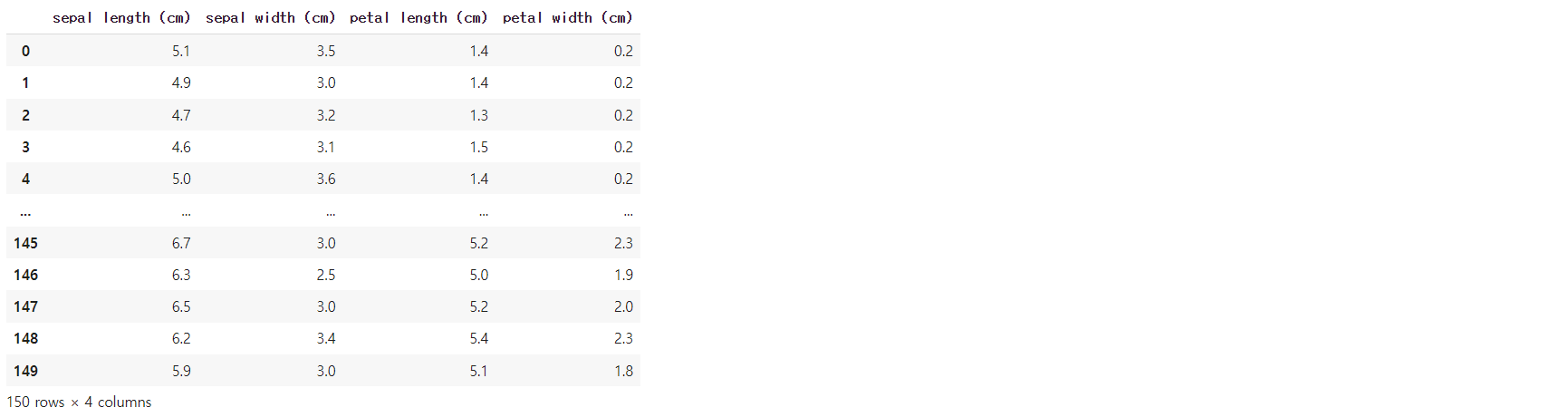
# 데이터셋에서 label(정답) 데이터 가져오기
target = iris.target
target
target.shape로 개수를 세어보면 150개의 샘플이 나온다.
# label 데이터를 데이터프레임에 추가하기
df_iris["target"] = target
df_iris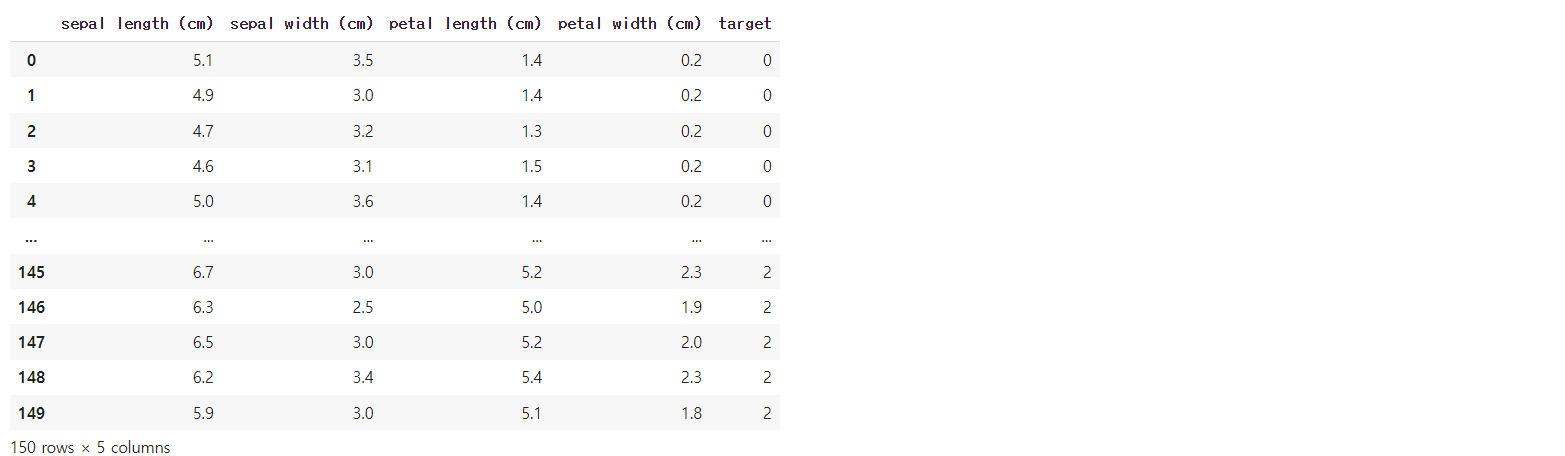
# scikit-learn 라이브러리에서 제공하는 함수로, 데이터 훈련용과 테스트용으로 나누는데 사용한다.
from sklearn.model_selection import train_test_split# train_test_split(독립변수, 종속변수, 테스트사이즈, 시드값, ...)
X_train, X_test, Y_train, Y_test = train_test_split(df_iris.drop("target", axis=1),
df_iris["target"],
test_size=0.2,
random_state=2023)# 모델 훈련용과 테스트용을 8:2로 나눈것이다.
X_train.shape, X_test.shape
120과 30은 데이터를 의미하고, 뒤에 나오는 4는 특징(feature), column값의 개수를 의미한다.
# 훈령용, 테스트용 label, 여기서는 target을 가져온 것이다.
y_train.shape, y_test.shape
# 데이터 확인
X_train
y_train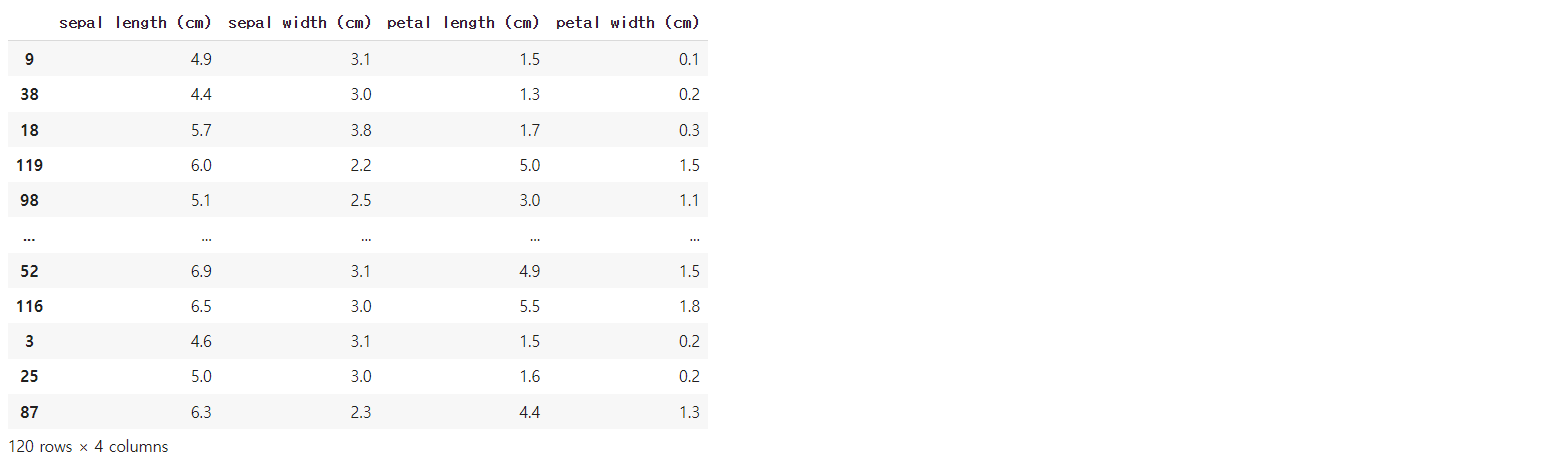

결과를 보면 데이터가 섞인 것을 볼 수 있는데, 위에서 random_state를 사용하였기에 섞여서 나온 것이다.
random_state를 사용하여 항상 같은 결과를 얻는다. 즉, 섞인 결과가 항상 같게 나온다.
# SCV 클래스는 scikit-learn에서 제공하는 SVM(Support Vector Machine) 모델 중 하나로 분류 문제에 사용된다.
# 데이터를 특성 공간(feature space)에서 선형 또는 비선형으로 분리하는 결정 경계를 찾는데 최적화된
# SVM 알고리즘을 구현한다.
# accuracy_score은 모델의 예측 결과와 실제 레이블을 비교하여 모델의 정확도를 계산하는데 사용된다.
# scikit-learn에서 제공하는 함수이다.
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score# 객체 생성
svc = SVC()
# 모델 훈련
svc.fit(X_train, Y_train)
이런 결과값이 나온다. 훈련이 완료된 것이라 볼 수 있다.
# 테스트 데이터(X_test)에 대한 예측
y_pred = svc.predict(X_test)
y_pred
테스트 데이터의 개수는 30개였으므로 30개가 나왔다.
# 예측값(y_pred)와 실제 정답(y_test)을 비교하여 정확도를 계산
print("정답률: ", accuracy_score(Y_test, y_pred))
100%의 정답률을 의미한다.
# 집적 다른값 넣어보기
# 6.2 2.1 4.1 1.5
y_pred =svc.predict([[6.2, 2.1, 4.1, 1.5]])
y_pred
1이란 값이 나온 것을 보면 iris-Versicolour 품종이란 것을 알 수 있다.
데이터셋 설명(DESCR)을 보면 feature(특징)과 함께 class부분이 있는데 그 값들 중 하나이다.
titanic DataSet
titanic DataSet에서는 데이터 전처리를 진행한다. 라벨 인코딩, 원 핫 인코딩도 사용한다.
데이터 전처리
- 데이터 정제 작업을 말한다.
- 필요없는 데이터를 삭제하고, null이 있는 행을 처리하고(무조건 제거하는 것이 아님), 정규화/표준화 등의 많은 작업들을 포함한다.
- 머신러닝, 딥러닝 실무에서 전처리가 차지하는 중요도는 50% 이상이라고 본다고 한다.
라벨 인코딩(Label Encoding)
- 문자(Categorical)을 숫자(Numerical)로 변환한다.
원 핫 인코딩(One Hot Encoding)
- 독립적인 데이터는 별도의 컬럼으로 분리하고 각각 컬럼에 해당하는 값에만 1, 나머지는 0의 값을 갖게 하는 방법이다.
# 데이터셋을 url로 가져와서 데이터프레임으로 변환
# titanic DataSet은 CSV파일 형식으로 제공
import pandas as pd
df = pd.read_csv("https://bit.ly/fc-ml-titanic")
df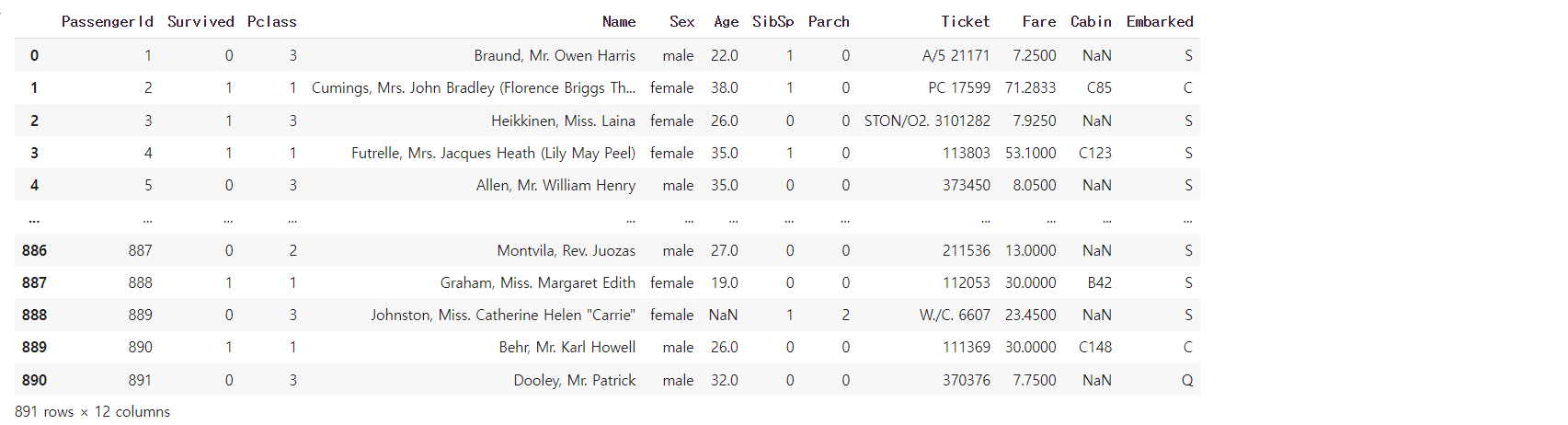

# 독립변수와 종속변수 나누기
# feature = ["Pclass", "Sex", "Age", "Fare"] # 독립변수
# label = ["Survived"] # 종속변수
columns = ["Pclass", "Sex", "Age", "Fare", "Survived"]
df[columns].head()
# 종속변수
df["Survived"].head()
# 종속변수 개수
df["Survived"].value_counts()
- 결측치 처리하기(전처리)
# 데이터프레임 정보 확인
df.info()
# null 값 확인
df.isnull().sum()
# null값의 평균
df.isnull().mean()
# 결측값(null)을 Age의 평균으로 채우기(fillna 사용)
df["Age"] = df["Age"].fillna(df["Age"].mean())
df["Age"]
- 라벨 인코딩(Label Encoding)
# 데이터프레임 정보 확인
df.info()
# 남자, 여자 수 확인
df["Sex"].value_counts()
# 남자는 1, 여자는 0으로 변환하는 함수
def convert_sex(data):
if data == "male":
return 1
elif data == "female":
return 0
# df["Sex"] = df["Sex"].apply(lambda x: 1 if x == "male" else 0)
df["Sex"] = df["Sex"].apply(convert_sex) # lambda함수를 사용해도 됨
df.head()
from sklearn.preprocessing import LabelEncoder
# 객체 생성
le = LabelEncoder()
df["Embarked"].value_counts() # null은 제거
# 라벨 인코딩
embarked = le.fit_transform(df["Embarked"])
embarked # null: 3
null 값은 3으로 나왔다.
# embarked의 value 값
le.classes_ # array(['C', 'Q', 'S', nan])
# 라벨 인코딩, fit_transform으로 'C', 'Q', 'S'의 값을 각각 0, 1, 2로 변환시켜준다.
# 결측값은 3으로 표시된다.
# LabelEncoder를 객체를 만들지 않고 바로 사용 가능하다.
df["Embarked_num"] = LabelEncoder().fit_transform(df["Embarked"])
df.head()
- 원 핫 인코딩(One Hot Encoding)
# 값에 맞는 건 True, 아닌건 False 표기
pd.get_dummies(df["Embarked_num"])
# 데이터프레임에 적용
df = pd.get_dummies(df, columns=["Embarked"])
df.head()
# 맨 처음에 만들어둔 우리가 사용할 변수(columns)들의 데이터프레임을 설정
df = df[columns]
df
# 우리가 사용할 데이터프레임에 적용
df = pd.get_dummies(df, columns=["Pclass", "Sex"])
df.head()
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(df.drop("Survived", axis=1),
df["Survived"],
test_size=0.2,
random_state=2024)# 모델 훈련용과 테스트용을 8:2로 나눈것이다.
X_train.shape, X_test.shape
# 훈령용, 테스트용 label
y_train.shape, y_test.shape
X_train
'Python > 머신러닝, 딥러닝' 카테고리의 다른 글
| Python 머신러닝 로지스틱 회귀 (0) | 2024.06.12 |
|---|---|
| Python 머신러닝 의사 결정 나무 (1) | 2024.06.11 |
| Python 머신러닝 선형회귀 (0) | 2024.06.11 |
| Python 머신러닝 Scikit-learn (0) | 2024.06.10 |
| Python 머신러닝 (0) | 2024.06.10 |