Bike DataSet
더보기
결과

결과

정보

결과

결과
결과

결과

결과

결과

결과

결과

결과

결과

결과
결과

결과

결과
결과

결과

결과

결과
결과

결과

결과

결과

결과

결과

결과

결과

결과

결과

결과
# 데이터셋 데이터프레임으로 읽기
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
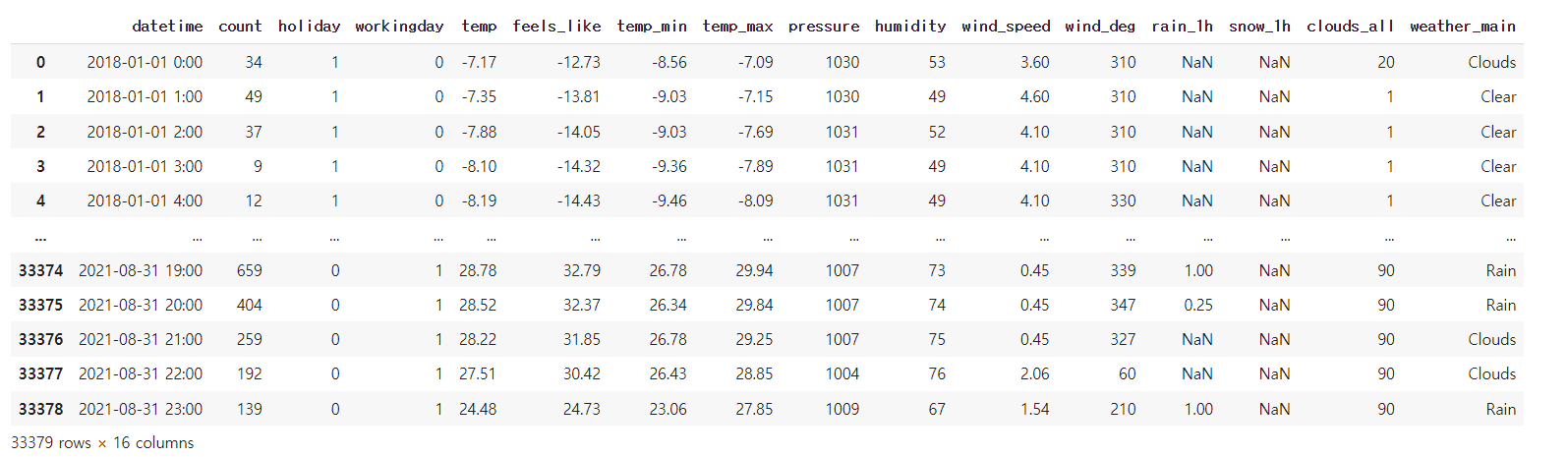
bike_df = pd.read_csv("/content/drive/MyDrive/KDT/7. 머신러닝과 딥러닝/데이터/bike.csv")
bike_df
# 데이터프레임 정보확인
bike_df.info()
# 통계정보
bike_df.describe()
# 막대 그래프
sns.displot(bike_df["count"])
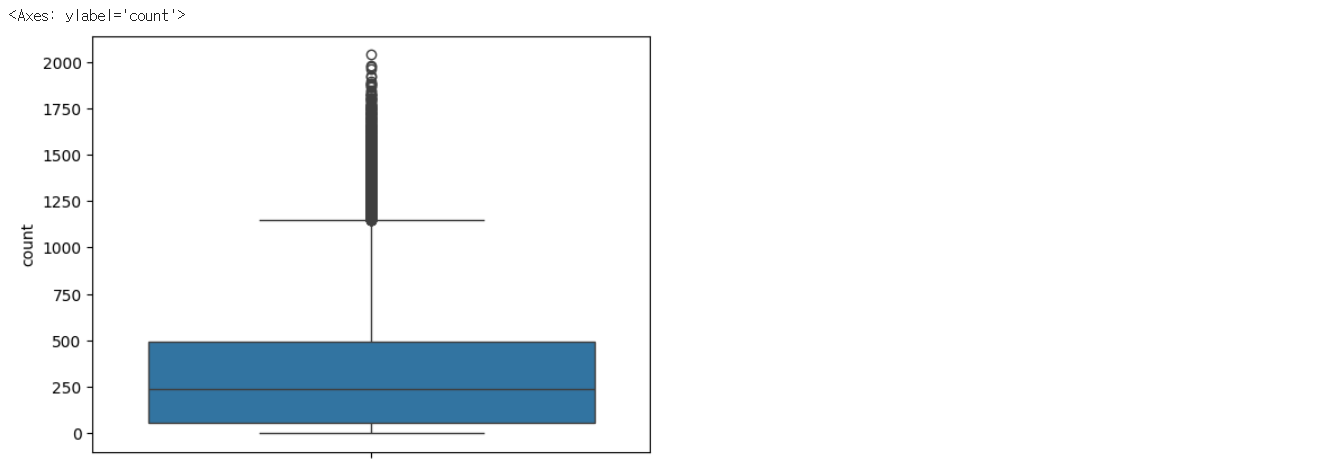
sns.boxplot(y=bike_df["count"])
sns.scatterplot(x="feels_like", y="count", data=bike_df, alpha=0.3)
sns.scatterplot(x="pressure", y="count", data=bike_df, alpha=0.3)
sns.scatterplot(x="wind_speed", y="count", data=bike_df, alpha=0.3)
sns.scatterplot(x="wind_deg", y="count", data=bike_df, alpha=0.3)
# null값 확인
# 매일 비가 오거나 눈이 오지는 않기 때문에
bike_df.isna().sum()
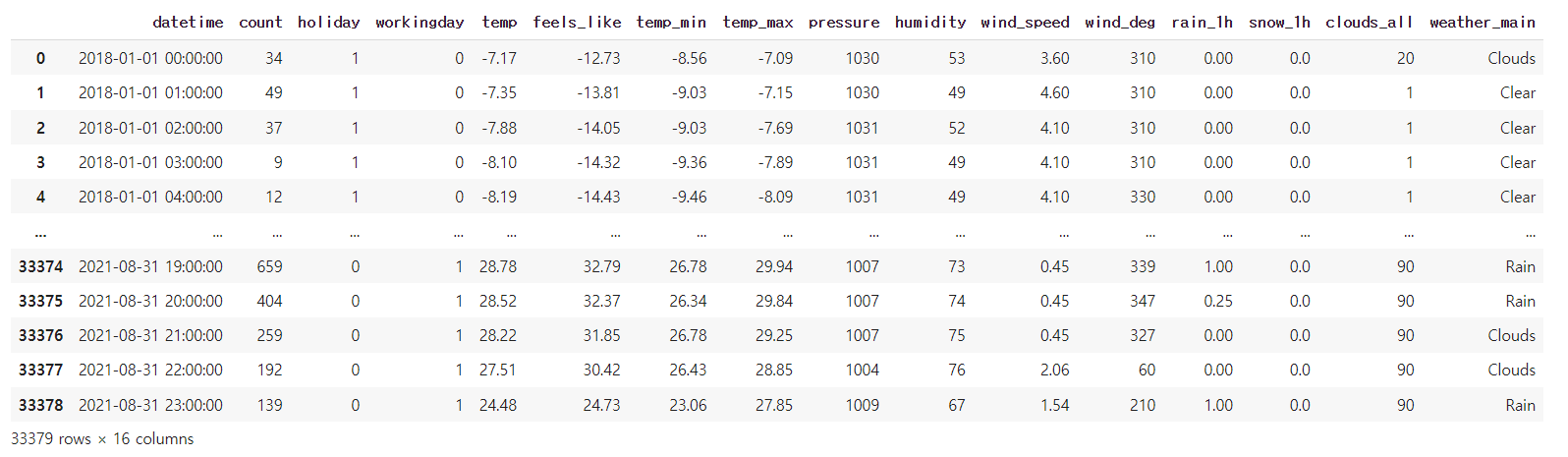
# 비오거나 눈오는 것을 평균값으로 채우기는 이상하니 0으로 채움
bike_df = bike_df.fillna(0)
bike_df.isna().sum()
# 데이터프레임 정보확인
bike_df.info()
# datetime으로 type 변환
bike_df["datetime"] = pd.to_datetime(bike_df["datetime"])
bike_df.info()
bike_df
# year, month, hour 파생변수 만들기
bike_df["year"] = bike_df["datetime"].dt.year
bike_df["month"] = bike_df["datetime"].dt.month
bike_df["hour"] = bike_df["datetime"].dt.hour
bike_df.head()
# date 파생변수 만들기
bike_df["date"] = bike_df["datetime"].dt.date
bike_df.head()
# 그래프
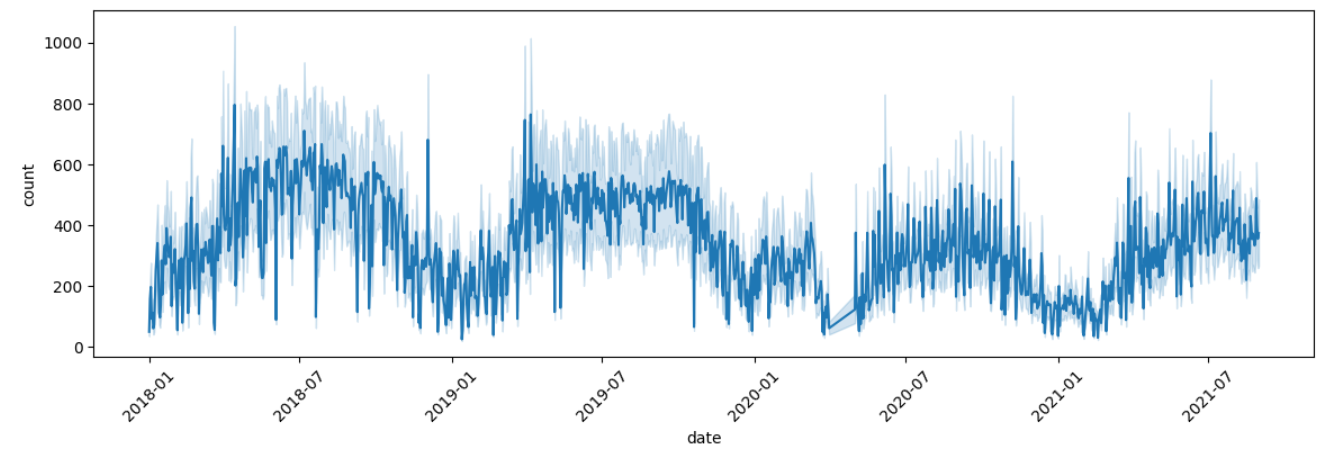
plt.figure(figsize=(14, 4))
sns.lineplot(x="date", y="count", data=bike_df)
plt.xticks(rotation=45)
plt.show()
# 2019년 월별 자전거 대여 개수를 출력
bike_df[bike_df["year"] == 2019].groupby("month")["count"].mean()
# 2020년 월별 자전거 대여 개수를 출력
# 4월 데이터가 없음
bike_df[bike_df["year"] == 2020].groupby("month")["count"].mean()
# covid
# 2020-04-01 이전: precovid
# 2020-04-01 이후 ~ 2021-04-01 이전: covid
# 2021-04-01 이후: postcovid
# 파생변수 covid
def covid(date):
if str(date) <= "2020-04-01":
return "precovid"
elif str(date) < "2021-04-01":
return "covid"
else:
return "postcovid"
bike_df["date"].apply(covid)
# 데이터프레임에 적용
bike_df["covid"] = bike_df["date"].apply(lambda date: "precovid" if str(date) < "2020-04-01"
else "covid" if str(date) < "2021-04-01"
else "postcovid")
bike_df
# season
# 12월 ~ 2월: winter
# 3월 ~ 5월: spring
# 6월 ~ 8월: summer
# 9월 ~ 11월: fall
def season(month):
if str(month) == '12' or str(month) <= '2':
return "winter"
elif str(month) >= '3' and str(month) <= '5':
return "spring"
elif str(month) >= '6' and str(month) <= '8':
return "summer"
else:
return "fall"
bike_df["month"].apply(season)
# 데이터프레임에 적용
bike_df["season"] = bike_df["month"].apply(lambda x: "winter" if x == 12
else "fall" if x >= 9
else "summer" if x >= 6
else "spring" if x>=3
else "winter")
bike_df[["month", "season"]]
# day_night
# 21시 이후: night
# 19시 이후: late evening
# 17시 이후: early evening
# 15시 이후: late afternoon
# 13시 이후: early afternoon
# 11시 이후: late morning
# 6시 이후: early morning
def day_night(hour):
if hour > 21 or hour < 6:
return "night"
elif hour > 19:
return "late evening"
elif hour > 17:
return "early evening"
elif hour > 15:
return "late afternoon"
elif hour > 13:
return "early atfernoon"
elif hour > 11:
return "late morning"
elif hour > 6:
return "early morning"
bike_df["hour"].apply(day_night)
# 데이터프레임에 적용
bike_df["day_night"] = bike_df["hour"].apply(lambda x: "night" if x >= 21
else "late evening" if x > 19
else "early evening" if x > 17
else "late afternoon" if x > 15
else "early afternoon" if x > 13
else "late morning" if x > 11
else "early morning" if x > 6
else "night")
bike_df[["hour", "day_night"]]
# 필요없는 변수(column) 제거
bike_df.drop(["datetime", "month", "date", "hour"], axis=1, inplace=True)
bike_df.head()
# 데이터프레임 정보확인
bike_df.info()
for i in ["weather_main", "covid", "season", "day_night"]:
print(i, bike_df[i].nunique())
bike_df["weather_main"].unique()
bike_df = pd.get_dummies(bike_df, columns=["weather_main", "covid", "season", "day_night"])
bike_df.head()
# column 전부 확인
pd.set_option("display.max_columns", 40)
bike_df.head()
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(bike_df.drop("count", axis=1), bike_df["count"],
test_size=0.2, random_state=2024)X_train.shape, y_train.shapeX_test.shape, y_test.shape
의사 결정 나무(Decision Tree)
- 데이터를 분석하고 파악하여 결정 규칙을 나무 구조로 나타는 기계학습 알고리즘이다.
- 간단하고 강력한 모델 중 하나로, 분류와 회귀 문제 모두 사용한다.
- 지니계수(지니 불순도, Gini Impurity): 분류 문제에서 특정 노드의 불순도를 나타내는데, 노드가 포함하는 클래스들이 혼잡되어 있는 정도를 나타낸다.
0에서 1까지의 값을 가지면, 0에 가까울수록 노드의 값이 불순도가 없음을 의미한다.
로그 연산이 없어 계산이 상대적으로 빠르다.
- 엔트로피: 어떤 집합이나 데이터의 불확실성, 혼잡도를 나타내며, 노드의 불순도를 측정하는데 활용한다.
0에서 무한대까지의 값을 가지며, 0에 가까울수록 노드의 값이 불순도가 없음을 의미한다.
로그 연산이 포함되어 있어 계산이 복잡하다.
- 오버피팅(과적합): 학습데이터에서는 정확하나 테스트데이터에서는 성과가 나쁜 현상을 말한다. 의사 결정 나무는 오버피팅이 매우 잘 일어난다.
오버피팅을 방지하는 방법
- 사전 가지치기: 나무가 다 자라기 전에 알고리즘을 멈추는 방법이다.
- 사후 가지치기: 나무를 끝까지 다 돌린 후 밑에서부터 가지를 쳐나가는 방법이다.
더보기

결과

결과

결과

결과
from sklearn.tree import DecisionTreeRegressor # 예측 모델
dtr = DecisionTreeRegressor(random_state=2024)
dtr.fit(X_train, y_train)
pred1 = dtr.predict(X_test)
pred1
# 그래프
sns.scatterplot(x=y_test, y=pred1)
from sklearn.metrics import mean_squared_errormean_squared_error(y_test, pred1, squared=False)
선형 회귀 VS 의사 결정 나무
더보기

결과

결과

결과

결과

결과

결과

결과

결과

결과
from sklearn.linear_model import LinearRegression
# 객체 생성
lr = LinearRegression()
lr.fit(X_train, y_train)
pred2 = lr.predict(X_test)
sns.scatterplot(x=y_test, y=pred2)
# 단위가 다름 0에서부터 선을 긋는다.
mean_squared_error(y_test, pred2, squared=False)
# 의사 결정 나무: 224.58514747450997
# 선형 회귀: 215.3214082808876
224.58514747450997 - 215.3214082808876
# 9.26373919362237
# 하이퍼 파라미터 적용
dtr = DecisionTreeRegressor(random_state=2024, max_depth=50, min_samples_leaf=30)
dtr.fit(X_train, y_train)
pred3 = dtr.predict(X_test)
mean_squared_error(y_test, pred3, squared=False)
# 의사 결정 나무: 224.58514747450997
# 선형 회귀: 215.3214082808876
# 의사 결정 나무(하이퍼 파라미터 적용): 180.9288999142024
180.9288999142024 - 224.58514747450997
# 43.65624756030758
# tree 그래프
from sklearn.tree import plot_tree# 그래프
plt.figure(figsize=(24, 12))
plot_tree(dtr, max_depth=5, fontsize=10)
plt.show()
# 그래프에 x값 나타내기
plt.figure(figsize=(24, 12))
plot_tree(dtr, max_depth=5, fontsize=10, feature_names=X_train.columns)
plt.show()
'Python > 머신러닝, 딥러닝' 카테고리의 다른 글
| Python 머신러닝 서포트 벡터 머신 (0) | 2024.06.12 |
|---|---|
| Python 머신러닝 로지스틱 회귀 (0) | 2024.06.12 |
| Python 머신러닝 선형회귀 (0) | 2024.06.11 |
| Python 머신러닝 DataSet - iris, titanic DataSet (0) | 2024.06.10 |
| Python 머신러닝 Scikit-learn (0) | 2024.06.10 |