Python 자연어 처리 개요
자연어(Natural Language)
- 프로그래밍 언어와 같이 인공적으로 만든 기계 언어와 대비되는 단어로, 우리가 일상에서 주로 사용하는 언어이다.
- 자연어 처리
- 컴퓨터가 한국어나 영어와 같이 인간의 자연어를 읽고 이해할 수 있도록 돕는 인공지능의 한 분야이다.
- 자연어에서 의미있는 정보를 추출하여 활용한다.
- 기계가 자연어의 의미를 이해하고 사람의 언어로 소통할 수 있게 한다.
- 자연어 처리의 활용
- 문서 분류, 스팸 처리와 같은 분류 문제
- 검색어 추천
- 음성 인식, 질의 응답, 번역
- 소셔 미디어 분석
- 자연어 처리의 용어
- 자연어 이해(NLU)
- 자연어 처리의 하위 집합이다.
- 일반적을로 기계가 자연어의 실제 의미, 의도나 감정, 질문 등을 사람차럼 이해하도록 돕는 것이다.
- 기계가 다양한 텍스트의 숨겨진 의미를 해석하려면 사전 처리 작업들과 추가 학습이 필요하다.
- 비 언어적 신호(표정, 손짓, 몸짓)도 힌트로 사용될 수 있다.
- 텍스트에서 의미 있는 정보를 추출하는 기술과 상황을 통계적으로 학습시킬 수 있는 다량의 데이터가 필요하다.
- 자연어 생성(NLG)
- 기계가 사람의 언어를 직접 생성하도록 돕는 기술이다.
- 기계가 일련의 계산 결과를 사람의 언어로 표현하도록 도와준다.
토크나이징
- 자연어 처리(NLP)에서 토크나이징(tokenizing)은 텍스트를 더 작은 단위로 분리하는 과정이다.
- 분리된 작은 단위를 토큰(token)이라고 부르며, 일반적으로 단어, 구두점, 숫자, 개별 문자일 수 있다.
- 토크나이징은 NLP의 초기 단계 중 하나로, 텍스트 데이터가 컴퓨터가 이해하고 처리할 수 있는 형태로 변환된다.
- 토크나이징은 어떻게 하느냐에 따라 성능의 차이가 날 수 있다.
- 영어의 토크나이징
- 공백 기반 토크나이징
- 공백을 기준으로 텍스트를 분리한다.
- 예) "I love natural language processing!" -> ["I", "love", "natural", "language", "processing", "!"]
- 구두점 처리
- 구두점을 단어와 분리하거나 별도의 토큰으로 처리한다.
- 예) "Hello, world!" -> ["Hello", ",", "world", "!"]
- 어간 추출 및 포제어 추출
- 단어의 형태를 정규화한다.
- 예) "running", "ran", "runner" -> "run"
- 어근 및 접사 분리
- 어절을 형태소로 분리하고 각 형태소의 품사를 태깅한다.
- 예) "저는 자연어 처리를 좋아합니다." -> [("저", "NP"), ("는", "JX"), ("자연어", "NP"), ("처리", "NP"), ("를", "JX"), ("좋아", "VV"), ("합니다", "VV")]
- 음정 단위 토크나이징
- 한글 음절 단위로 분리한다.
- 예) "안녕하세요" -> ["안", "녕", "하", "세", "요"]
한국어는 조사, 어미 등과 문법적 요소가 풍부하고, 공백이 의미 단위의 경계를 항상 명확하게 나타내지 않기 때문에 형태소 분석이 중요한 역할을 함
형태소 분석
- 자연어의 문장은 형태소라는 최소 단위를 분할하고 품사를 판별하는 작업이다,
- 영어 형태소 분석은 형태소마다 띄어쓰기를 해서 문장을 구성하는 것이 기본이다.(분석이 쉬운 편)
- 아시아 계열의 언어 분석은 복잡하고 많은 노력이 필요하다.
- 한국어 형태소 분석 라이브러리: KoNLPy
- 명사, 대명사, 수사, 동사, 형용사, 관형사, 부사, 조사, 감탄사 총 9가지를 분석한다.
- Hannanum, KKma, Komoran, Okt 분석기 포함한다.
!pip install KoNLPy
# corpus가 붙으면 말뭉치라고 생각..
# 데이터 뭉치?
# kolaw: 대한민국 헌법 텍스트 파일이 들어있음
from konlpy.corpus import kolaw
kolaw.fileids()
# 파일 읽기
law = kolaw.open("constitution.txt").read()
law
from konlpy.tag import *
hannanum = Hannanum()
kkma = Kkma()
komoran = Komoran()
okt = Okt()
law[:100]
# 명사만 추출
okt.nouns(law[:100])
# pos: 태깅정보 확인
okt.pos(law[:100])
# 형태소를 알려준다.
okt.tagset
text = "아버지가방에들어가신다"
okt.pos(text)
text = "아버지가 방에 들어가신다"
okt.pos(text)
okt.pos("오늘 날씨가 참 꾸리꾸리 하네욬ㅋㅋㅋㅋㅋㅋㅋㅋㅋ")
# norm=True: 각 형태소에 댛한 원형으로 처리
okt.pos("오늘 날씨가 참 꾸리꾸리 하네욬ㅋㅋㅋㅋㅋㅋㅋㅋ", norm=True)
# stem=True: 원형으로 변경
okt.pos("오늘 날씨가 참 꾸리꾸리 하네욬ㅋㅋㅋㅋㅋㅋㅋㅋ", norm=True, stem=True)
워드 클라우드
- 핵심 단어를 시각화하는 기법이다.
- 문서의 키워드, 개념 등을 직관적으로 파악할 수 있게 핵심 단어를 시각적으로 돋보이게 한다.
# wordcloud 설치
!pip install wordcloud
# import
from wordcloud import WordCloud
# 파일 읽기
text = open("/content/drive/MyDrive/KDT/8.자연어 처리/Data/alice.txt").read()
text
# generate(): 단어별 출현 빈도수를 비율로 반환하는 객체를 생성
wordcloud = WordCloud().generate(text)
wordcloud
# 빈도수 확인
wordcloud.words_
# 모듈 import
import matplotlib.pyplot as plt
# 이미지로 나타내기
plt.figure(figsize=(12, 8))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
# max_words: 원드 클라우드에 표시되는 단어의 개수를 설정
wordcloud = WordCloud(max_words=100).generate(text)
plt.figure(figsize=(12, 8))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
# nanum 관련 폰트 모두 설치
!apt-get update -qq
!apt-get install fonts-nanum* -qq
import matplotlib.font_manager as fm
# 폰트 확인(경로)
sys_font = fm.findSystemFonts()
[f for f in sys_font if 'Nanum' in f]

# 위에서 긁어서 font_path에 넣어줌, 폰트 변경
wordcloud = WordCloud(max_words=100, font_path="/usr/share/fonts/truetype/nanum/NanumPen.ttf").generate(text)
plt.figure(figsize=(12, 8))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
from PIL import Image
import numpy as np
alice_mask = np.array(Image.open("/content/drive/MyDrive/KDT/8.자연어 처리/Data/alice_mask.png"))
alice_mask
# mask에 적용
wordcloud = WordCloud(max_words=100, font_path="/usr/share/fonts/truetype/nanum/NanumPen.ttf",
mask=alice_mask,
background_color="ivory").generate(text)
plt.figure(figsize=(12, 8))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()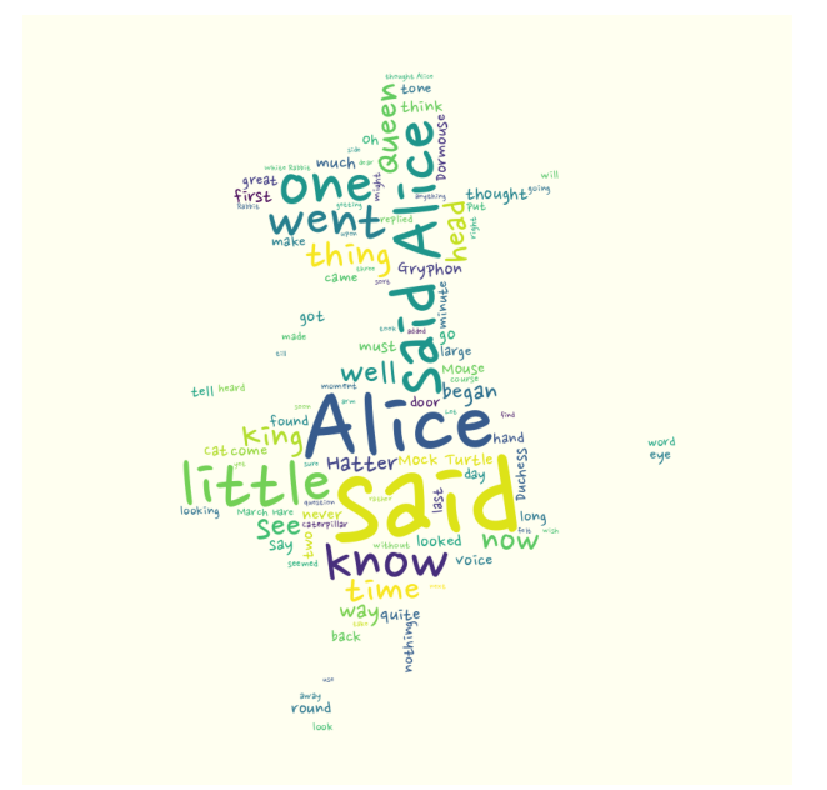
문제
- konlpy.corpus 말뭉치 중 kolaw의 "constitution.txt"를 읽어서 명사만 추출한 후에 글자수가 한 자인 명사는 제거 후 빈도수에 따른 워드 클라우드를 지도 위에 표시하기
law = kolaw.open("constitution.txt").read()
law
# 명사만 뽑기
nouns = okt.nouns(law)
print(nouns)
# 글자수대로 정렬보기
nouns.sort(key=lambda x: len(x))
print(nouns)
# 글자수가 한 자인 명사 제거
nouns = [word for word in nouns if len(word) > 1]
print(nouns)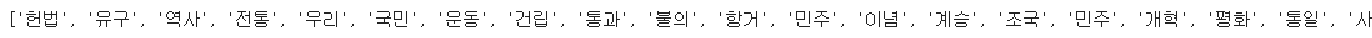
from collections import Counter
# 숫자를 세주는 함수 Counter
count = Counter(nouns)
print(count)
# 가장 count높은 100가지를 가져옴
data = count.most_common(100)
data = dict(data)
print(len(data))
print(data)
# mask 생성
mask = np.array(Image.open("/content/drive/MyDrive/KDT/8.자연어 처리/Data/korea_mask.jpg"))
# generate_from_frequencie: dict 형태의 구조를 받아서 사용할 수 있다.
# generate: text 형태로 받아야함
wordcloud = WordCloud(max_words=100, font_path="/usr/share/fonts/truetype/nanum/NanumPen.ttf",
mask=mask,
background_color="ivory").generate_from_frequencies(data)
plt.figure(figsize=(12, 8))
plt.imshow(wordcloud)
plt.axis("off")
plt.show()