Credit Dataset
# 필요한 모듈
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt# credit 데이터셋 데이터프레임으로 읽어오기
credit_df = pd.read_csv("파일경로")
credit_df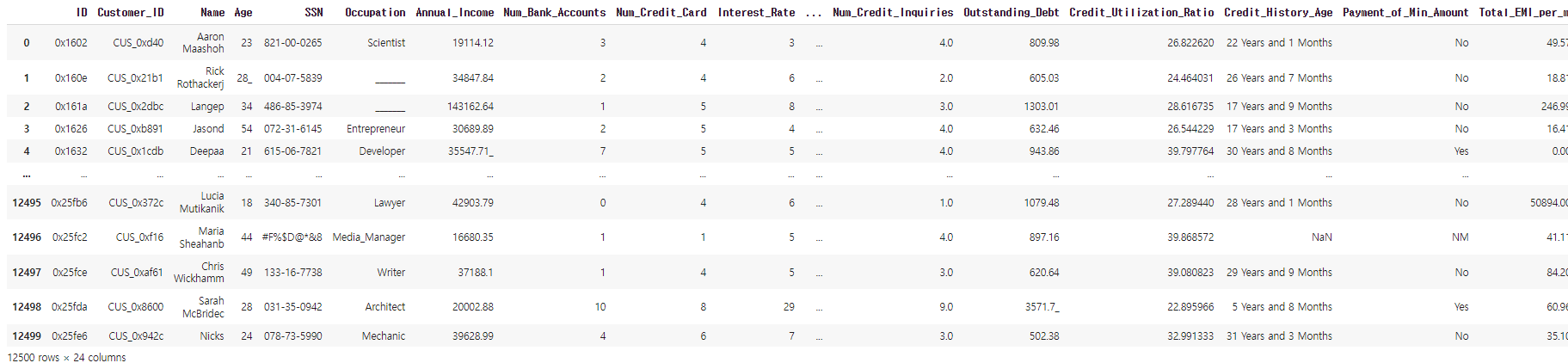
# 데이터프레임 정보확인
credit_df.info()

# 사용하지 않을 column 제외
credit_df.drop(["ID", "Customer_ID", "SSN", "Name"], axis=1, inplace=True)
# 다시 정보확인
credit_df.info()
# Credit_Score의 값들 확인
credit_df["Credit_Score"].value_counts()
# Credit_Score의 값들을 숫자로 변경
credit_df["Credit_Score"] = credit_df["Credit_Score"].replace({"Poor": 0, "Standard": 1, "Good": 2})
credit_df.head()
# 데이터프레임 통계정보 확인
credit_df.describe()
# corr() 함수로 관계성 한번에 확인하기
plt.figure(figsize=(12, 12))
sns.heatmap(credit_df.corr(numeric_only=True), cmap="coolwarm", vmin=-1, vmax=1, annot=True)
# dtype이 object인 것들 확인
for i in credit_df.columns:
if credit_df[i].dtype == 'O':
print(i)
# column에 값들 중 _로 되어있는게 있음
# _지우기
for i in ["Age", "Annual_Income", "Num_of_Loan", "Num_of_Delayed_Payment", "Outstanding_Debt", "Amount_invested_monthly"]:
credit_df[i] = pd.to_numeric(credit_df[i].str.replace('_', ''))
# 다시 정보확인
credit_df.info()
# Credit_History_Age 값 확인
credit_df["Credit_History_Age"]
# Credit_History_Age의 데이터를 개월로 변경
# 22 Year and 1 Months -> 22 * 12 + 1 = 265
credit_df['Credit_History_Age'] = credit_df['Credit_History_Age'].str.replace(' Months', '')
# 22 Year and 1
# expand=True 데이터프레임으로 만들어줌
credit_df['Credit_History_Age'] = pd.to_numeric(credit_df['Credit_History_Age'].str.split(' Years and ', expand=True)[0])*12 + pd.to_numeric(credit_df['Credit_History_Age'].str.split(' Years and ', expand=True)[1])
credit_df.head()
# Age column 값 확인
sns.boxplot(y=credit_df["Age"])
# 나이가 110세 미만의 값만 저장한다.
credit_df = credit_df[credit_df["Age"] < 110]
# 카드를 갖고있는 개수를 20개로 제한
credit_df = credit_df[credit_df["Num_Credit_Card"] <= 20]
# 통계정보 확인
credit_df.describe()
# 이자 40퍼센트 이하로 제한
credit_df = credit_df[credit_df["Interest_Rate"] <= 40]
# 통계정보 확인
credit_df.describe()
# 대출 수는 20 이하로 제한
credit_df = credit_df[(credit_df["Num_of_Loan"] <= 20) & (credit_df["Num_of_Loan"] >= 0)]
# 통계정보 확인
credit_df.describe()
# 연체 기간이 0보다 큰 값으로 제한
credit_df = credit_df[credit_df["Delay_from_due_date"] >= 0]
# 연체된 결제 수를 30개 이하로 제한
credit_df = credit_df[(credit_df["Num_of_Delayed_Payment"] < 30) & (credit_df["Num_of_Delayed_Payment"] >= 0)]
# 통계정보 확인
credit_df.describe()
# Num_Credit_Inquiries의 null값을 0으로 대체
credit_df["Num_Credit_Inquiries"] = credit_df["Num_Credit_Inquiries"].fillna(0)# 데이터프레임 결측값(null값) 확인
credit_df.isna().mean()
# 막대그래프로 확인
sns.displot(credit_df["Credit_History_Age"])
sns.displot(credit_df["Amount_invested_monthly"])
sns.displot(credit_df["Monthly_Balance"])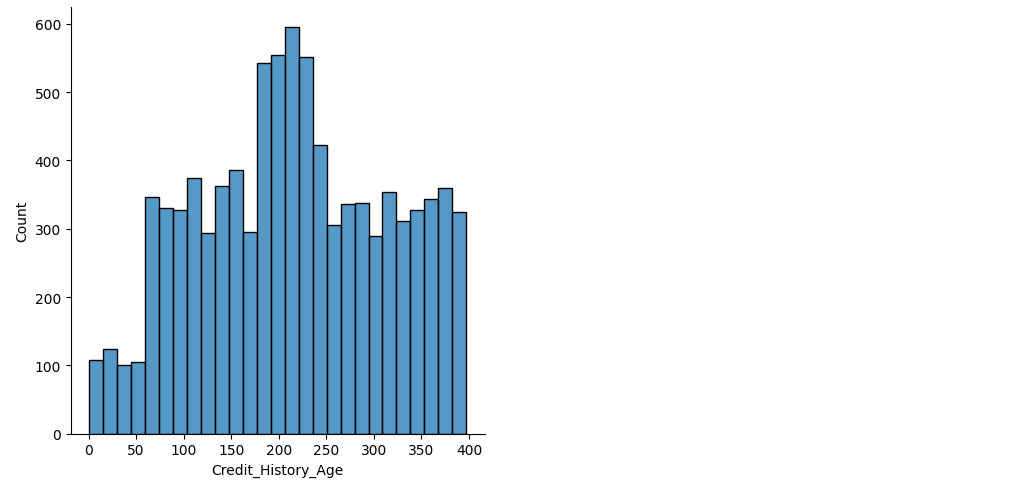


# 그래프를 보면 평균값을 내면 있지도 않은 값을 다수 넣게 된다.
# 따라서 중간값을 넣기로 함
credit_df = credit_df.fillna(credit_df.median(numeric_only=True))
# 결측값 확인
credit_df.isna().mean()
# 문제
# Type_of_Loan의 모든 대출 상품을 변수에 저장
# NaN인 데이터는 "No Loan"으로 대체
# 대출상품 만큼의 컬럼을 만들고 해당 대출 상품을 받았다면 1 아니면 0으로 데이터 처리
# Auto Loan, Auto Loan and Not Specified => Auto Loan, Auto Loan, Not Specified
credit_df["Type_of_Loan"] = credit_df["Type_of_Loan"].str.replace("and ", '')
# NaN인 데이터는 "No Loan"으로 대체
credit_df["Type_of_Loan"] = credit_df["Type_of_Loan"].fillna("No Loan")
# 각 값을 추출하기, 같은 값은 set을 사용하여 한번만 표현됨
type_list = set(credit_df["Type_of_Loan"].str.split(", ").sum())
# 대출상품 만큼의 컬럼을 만들고 해당 대출 상품을 받았다면 1 아니면 0으로 데이터 처리
for i in type_list:
credit_df[i] = credit_df["Type_of_Loan"].apply(lambda x: 1 if i in x else 0)
# Type_of_Loan 제외
credit_df.drop("Type_of_Loan", axis=1, inplace=True)
credit_df.info()
# Occupation
# "-----"를 "Unknown"로 바꿈
credit_df["Occupation"] = credit_df["Occupation"].str.replace("_______", "Unknown")
credit_df.head()
# Payment_Behaviour
# "!@9#%8"를 "Unknown"로 바꿈
credit_df["Payment_Behaviour"] = credit_df["Payment_Behaviour"].str.replace("!@9#%8", "Unknown")
credit_df["Payment_Behaviour"].value_counts()
# 위 Object를 원핫인코딩
credit_df = pd.get_dummies(credit_df, columns=["Occupation", "Payment_of_Min_Amount", "Payment_Behaviour"])
credit_df.info()
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(credit_df.drop("Credit_Score", axis=1),
credit_df["Credit_Score"],
test_size=0.2,
random_state=2024)
X_train.shape, y_train.shape, X_test.shape, y_test.shape
lightGBM(LGBM)
- Microsoft에서 개발한 Gradient Boosting Framework이다
- 리프 중심 히스토그램 기반의 알고리즘이다.
- 작은 데이터셋에서도 높은 성능을 보이며, 특히 대용량 데이터셋에서 다른 알고리즘보다 빠르게 학습한다.
- 메모리 사용량이 상대적으로 적은 편이다.
- 적은 데이터셋을 사용할 경우 과적합 가능성이 매우 크다.(일반적으로 데이터가 10,000개 이상은 있어야 함)
과적합 : 학습에 친화적인고 테스트는 엉망, train 데이터는 좋은데 test 데이터는 성능이 안 좋음
- 조기 중단(early stopping)
- 리프 중심 히스토그램 기반 알고리즘

- 트리를 균형적으로 분할할 것이 아니라, 최대한 불균형하게 분할한다.
- 특성들의 분포를 히스토그램으로 나타내고, 해당 히스토그램을 이용하여 빠르게 후보 분할 기준을 선택한다.
- 후보 분할 기준 중에서 최적의 분할 기준을 선택하기 위해, 데이터 포인트들을 히스토그램에 올바르게 배치하고, 이를 이용하여 최적의 분할기준을 선택한다.
- GBM(Gradient Boosting Model)
- 순차적으로 모델을 학습 시킨다.
- 첫 번째 모델을 학습시키고, 두 번째 모델은 첫 번째 모델의 오류를 학습하는 식으로 진행(이런 방식으로 각 모델이 이전 모델의 오류를 보완한다.
- 부스팅에서는 각 데이터 포인트에 가중치를 부여. 초기에는 모든 데이터 포인트에 가중치를 부여하지만, 이후 모델이 학습되면서 잘못 예측된 데이터 포인트의 가중치를 증가시켜 다음 모델이 이 데이터 포인트에 더 주의를 기울이도록 한다.
- 트리가 모두 학습된 후 예측 결과를 결합하여 최종 예측을 만드는데 일반적으로 분류 문제에서는 다수결 투표 방식으로, 회귀 문제에서는 예측값의 평균을 사용한다.
- 부스팅 모델의 주요 개념
- 약한 학습기(Wesk Learner): 단독으로 성능이 좋지 않은 간단한 모델(주로 깊이가 얕은 결정 트리, 깊이가 1인 매우 간단한 학습기)을 사용한다.
- 약한 학습기를 순차적으로 학습시키고 그다음에는 첫 번째 학습기의 오류를 보완하는 두 번째 학습기를 학습시킨다.
# import
from lightgbm import LGBMClassifier
# 객체 생성
base_model = LGBMClassifier(random_state=2024)
# 훈련
base_model.fit(X_train, y_train)
# 예측
pred = base_model.predict(X_test)
# 평가지표 import
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report, roc_auc_scoreaccuracy_score(y_test, pred)
confusion_matrix(y_test, pred)
print(classification_report(y_test, pred))
proba = base_model.predict_proba(X_test)
proba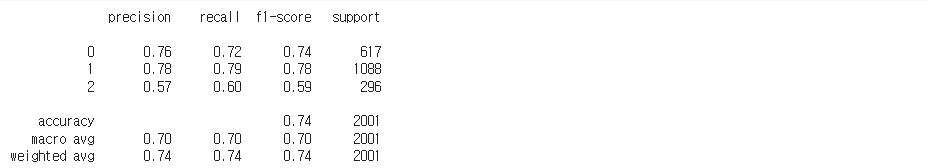
proba = base_model.predict_proba(X_test)
proba
roc_auc_score(y_test, proba, multi_class="ovr")
'Python > 머신러닝, 딥러닝' 카테고리의 다른 글
| Python 머신러닝, 딥러닝 파이토치 (0) | 2024.06.18 |
|---|---|
| Python 머신러닝 다양한 모델 적용하기 (0) | 2024.06.17 |
| Python 러닝머신 랜덤 포레스트 (0) | 2024.06.15 |
| Python 머신러닝 서포트 벡터 머신 (0) | 2024.06.12 |
| Python 머신러닝 로지스틱 회귀 (0) | 2024.06.12 |